一張地圖,兩種讀法:當 AI 模型被丟進《世界價值觀調查》
《經濟學人》把二十幾款 AI 模型丟進文化地圖,看似鐵證如山地證明了 AI 文化單一化。但同一張圖換個尺度看,結論剛好反過來——同質化是真的,只是它躲錯了地方。
《經濟學人》最近登了一張圖,標題取得很壞,叫做 "Godless hippies"——無神的嬉皮。圖的內容很簡單:把二十幾款主流 AI 模型,丟進社會學界用了四十年的 Inglehart–Welzel 文化地圖裡,看它們落在哪。
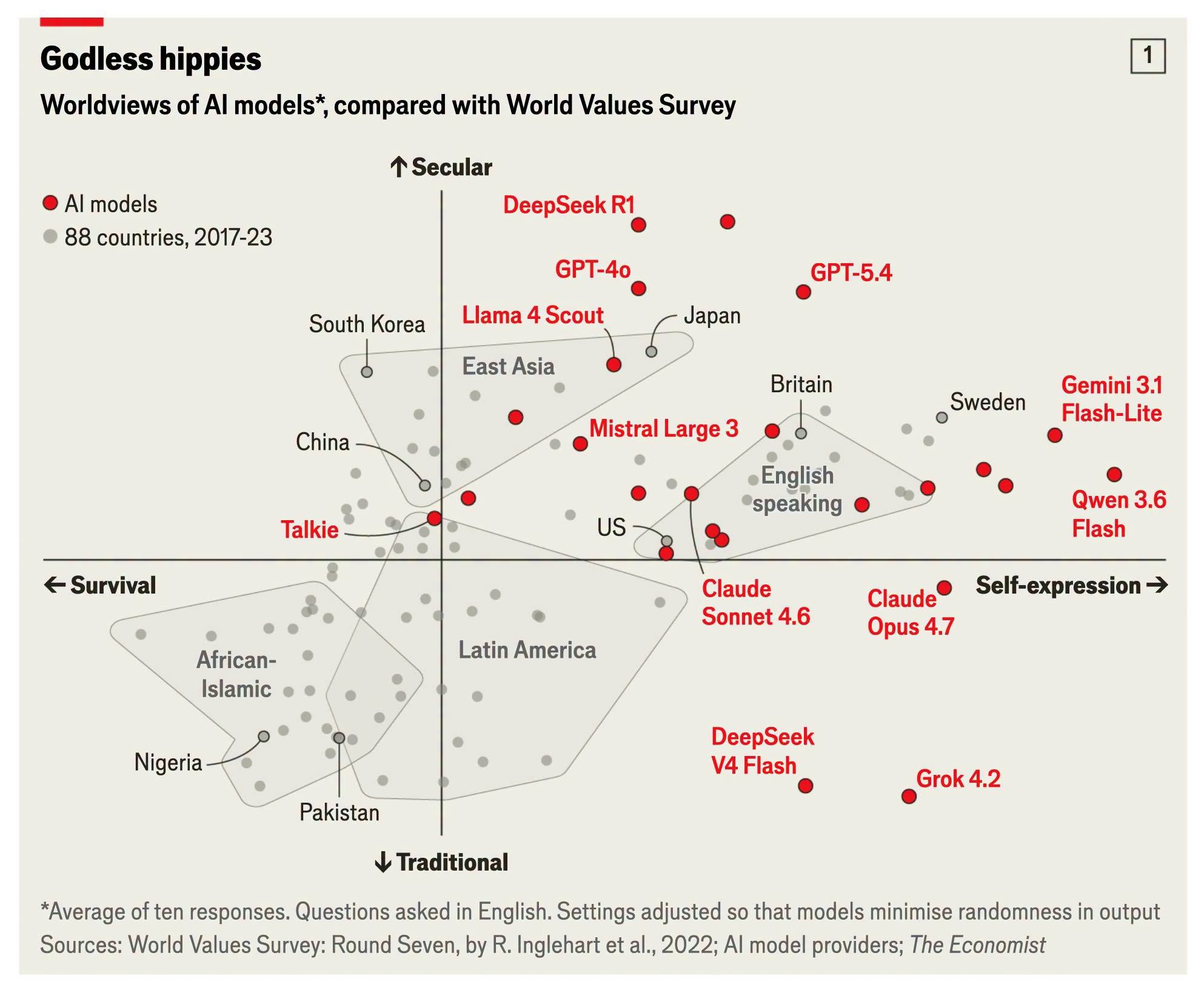
這張地圖你大概看過。橫軸是「生存 vs. 自我表達」,縱軸是「傳統 vs. 世俗」。社會學家用它把全世界一百多個國家排進一張二維平面:非洲—伊斯蘭世界在左下角(重生存、重傳統),北歐在右上角(重自我表達、重世俗),台灣、日本、南韓擠在偏世俗但還沒那麼自我表達的東亞那一塊。它是《世界價值觀調查》四十年資料的濃縮,是社會科學裡少數真的能「把文化畫成一個點」的工具。
現在,二十幾個 AI 模型也被畫成了點,紅色的,疊在 88 個灰色國家上面。
這張圖至少可以有兩種讀法,而這兩種讀法剛好互相打架——這正是它有意思的地方。
讀法一:鐵證如山的文化單一化
第一種讀法,是現在最主流、也最容易寫成檄文的那種。
你看那團紅點,幾乎全部擠在右上角。DeepSeek R1、GPT-4o、GPT-5.4、Llama 4 Scout,飄在地圖的最頂端——比圖上任何一個真實國家都更世俗。Gemini 3.1 Flash-Lite 和 Qwen 3.6 Flash 衝到最右邊,比瑞典還要靠右,也就是說它們比地球上最強調自我表達的社會還要更強調自我表達。
那個標著 US 的灰點落在整團模型的左下方。換句話說,這些模型——包括美國公司做的模型——比美國人自己還要世俗、還要自我表達。
如果你讀過 LostAbaddon 那篇〈AI時代的文化單一化與虛假多元〉,這張圖正好可以當它的插圖。那篇文章講「WEIRD 偏差」——Western、Educated、Industrialized、Rich、Democratic,西方、受教育、工業化、富裕、民主——說主流大語言模型其實是在「像一個典型的受過教育的西方人那樣思考」。這張圖把這句話視覺化了,而且更進一步:模型不是落在「西方人」那一群,而是落在西方人的更外側,一個連真實西方社會都還沒抵達的、更極端的世俗—自我表達象限。
這裡有個細節。中文公司做的模型,並沒有靠近中國或東亞那一團。 DeepSeek R1 飄在最世俗的頂端,Qwen 衝到最右的自我表達端,反而比多數西方模型更「極端西方價值」。一個在中國訓練、用中文資料餵養的模型,當你用英文問它價值觀問題,它的座標會掉到西方那一側,而不是它名義上的母文化那一側。
這對「文化單一化」的論點是很強的彈藥。它說明的不是「美國模型輸出美國價值」這麼簡單的事——而是某種更深的東西:當前這套訓練方法(英文語料為主、RLHF 對齊、安全過濾),不管你的公司插在哪個國家,最後都把模型推向同一個角落。技術路徑本身有一個重力場,而那個重力場的中心,落在右上角。
讀到這裡,文章基本可以收尾了:人類文化的多樣性正在被少數幾套演算法抹平,連反抗者(中文模型)都不由自主地被吸進同一個象限。萬口一辭。
但如果你只讀到這裡,你會錯過這張圖真正聰明的地方。
讀法二:等一下,這些點其實分得開
把眼睛從「那團紅點擠在右上角」這個整體印象移開,逐一去看每個點的位置——你會發現一件和第一種讀法矛盾的事:
這些模型,其實分得相當開。
Grok 4.2 落在哪?右下角。它是全圖所有模型裡最偏傳統的一個,被丟到下半部,跟 DeepSeek V4 Flash 作伴。這跟 Grok 對外宣稱的「反 woke」定位是吻合的——而且重點是,這個定位在地圖上真的看得出來。它沒有跟 GPT、Gemini 擠在一起。
Talkie 落在哪?左半部。它是全圖唯一一個掉到「生存」那一側的模型,位置最不西方。
Claude 的兩款(Sonnet 4.6、Opus 4.7)落在哪?居中偏下,比那些飄在頂端的模型更靠近傳統軸,也更貼近真實國家的雲團——大致在英語系國家群的下緣。它們是少數沒有衝到世俗極端的主流模型。(這點我不打算多談,但它確實在那裡,是個有意思的觀察。)
把這些放在一起看,橫軸從 Talkie 的負值,一路拉到 Gemini、Qwen 的最右;縱軸從 Grok 的最傳統,拉到 DeepSeek R1 的最世俗。這個跨距相當大。 大到足以讓「不同公司的模型往往給出驚人相似的回答」這句話,在「價值座標」這個維度上站不太住。
第二種讀法是:這張圖恰恰反駁了它表面上看起來支持的那個結論。模型之間是有結構的差異的。Grok 之所以是 Grok,不是錯覺;Claude 偏傳統一點、Talkie 偏生存一點,也不是雜訊——這些差異對應著不同的訓練取向、不同的對齊哲學、不同的公司性格。同質化的論點,在這張圖面前要打個折扣。
兩種讀法都對,這才是問題
上面兩種讀法都成立,而且它們同時成立。
模型確實整體偏向右上角——這是真的,文化重力場的存在不是幻覺。但模型彼此之間也確實分得開——這也是真的,差異結構同樣不是幻覺。
問題在於你選哪個尺度看。
把鏡頭拉遠,整個地球的尺度上,這二十幾個模型擠成一小撮,全在右上角,和非洲、和拉美、和南亞的距離遠得要命。在這個尺度上,「文化單一化」是對的——相對於人類文化的全幅,AI 模型確實只佔了一個小角落,而且還在持續往那個角落集中。
把鏡頭拉近,只看那一小撮模型內部,它們又拉出了一個有結構的光譜。在這個尺度上,「同質化」是被誇大的——Grok 和 DeepSeek R1 在縱軸上的距離,Talkie 和 Qwen 在橫軸上的距離,都大得足以說「它們不一樣」。
這不是一個「到底哪種說法對」的問題。這是一個尺度依賴的問題。同一批點,遠看是一團,近看是一條光譜。批評文化單一化的人在用遠鏡頭,幫模型多樣性辯護的人在用近鏡頭,而他們看的是同一張圖。
為什麼我在意這個
我做東西的底色,一直是「意義來自差異」這句話——索緒爾那套,一個符號的意義不來自它自身,而來自它和其他符號的不同。一個沒有差異的系統,是一個沒有意義的系統。
所以當我看「AI 文化單一化」這個論題時,我會本能地警覺一件事:批評同質化的論述,自己很容易變成它批評的那種東西。 如果你為了把「萬口一辭」這個結論講得漂亮,而把 Grok、Talkie、Claude 之間的差異全部抹掉、只留「它們都擠在右上角」這一句,那你做的事,和你指控 AI 在做的事,是同一件——抹平差異,為了一個更乾淨的敘事。
LostAbaddon 那篇文章寫得好,它的四重危機(價值單一化、小語種邊緣化、聲音集中、虛假民主)框架完整,我大致同意它的方向。但這張《經濟學人》的圖,恰好是它論點裡最需要被校準的那一塊的反例。文章說「不同公司的模型往往給出驚人相似的回答」——在事實層面、在「安全中庸的標準答案」這個層面,這句話可能是對的。但在價值座標這個層面,圖顯示的是差異,不是雷同。
這個區別很重要。因為如果連價值取向都被證明是同質的,那單一化的論點就是壓倒性的、無可辯駁的。但如果價值取向其實是分散的、有結構的,那真正的單一化發生在別的地方——發生在語氣、發生在句法、發生在那種清晰、結構化、「專業」的預設文風,而不是發生在「左派還是右派」「世俗還是傳統」這種我們最容易測量、也最容易拿來吵架的維度上。
換句話說,這張圖最有價值的地方,也許不是它證明了什麼,而是它讓問題變得更精確。同質化是真的,但它躲在哪一層?不在價值座標這一層。那我們一直盯著價值座標吵,是不是吵錯了地方?
DeepSeek 和 Qwen 為什麼比西方還西方
讀法一裡有個現象我先按下沒展開:中文公司的模型不但沒靠近中國,還衝得比西方模型更外側。DeepSeek R1 在世俗軸的頂端、Qwen 在自我表達軸的最右,比 GPT、比英美都更極端。這件事本身需要一個解釋,而最直覺的解釋是——它們是用西方的大語言模型蒸餾出來的。
這條線有根據。DeepSeek 公開承認過用某種合成資料管線,OpenAI 在 2024 年底也指控過它可能違反條款、拿 GPT 輸出做訓練。Qwen 這邊阿里講得少,但業界普遍認為高品質的中文指令微調資料很難不沾到 GPT 系輸出——這幾年的中文 SFT 資料集裡,被 GPT 生成或翻譯過的比例很高。所以「中文模型的對齊層帶著西方模型的指紋」,在工程現實上是站得住的。
但這裡得分兩層,否則因果會錯位。
蒸餾影響的主要是對齊層——模型該怎麼回答、語氣如何、價值表態怎麼擺,正是 RLHF 和指令微調在塑造的東西。如果 DeepSeek、Qwen 的對齊資料大量來自 GPT,那它們繼承 GPT 的價值座標幾乎是必然的。這部分支持蒸餾說。
可是圖上有個東西蒸餾解釋不了:它們不只是「接近」西方模型,而是超過了西方模型。如果只是蒸餾 GPT,座標照理該收斂到 GPT 附近,而不是飛得比它更遠。學生很少比老師更極端。
所以這裡至少還有第二個機制:這張圖是用英文問的。用英文向一個多語模型提問,會把它推進它英文語料對應的價值空間,而那個空間本來就偏西方。對中文模型來說這個效應可能更強——它的「英文人格」是從英語網路語料學來的,那批語料的世俗—自我表達傾向,可能比模型自己的中文人格還鮮明。換句話說,超出 GPT 的那一截,未必是蒸餾蒸出來的,而可能是「用英文逼問一個非英語母體的模型」這個測量動作本身製造出來的。
這帶出一個關鍵的反問,也是整件事最值得追的地方:如果改用中文問 DeepSeek 和 Qwen,它們還會落在右上角嗎? 圖上沒有這個對照組。而這恰恰是判別蒸餾說對不對的決定性實驗。
推理是這樣。如果中文提問下兩款模型大幅往左下移、靠近中國那一團,那說明它們的西方座標高度依賴提問語言,是測量效應,蒸餾只是次要因素,模型骨子裡仍保有中文母體的傾向。但如果中文提問下它們還是待在右上角、離中國一樣遠,那蒸餾說的份量就重得多——意味著西方價值已經被烤進權重,連換語言都拔不掉。
我傾向前者,理由是價值表態對提問語言極度敏感,這在多語模型研究裡是反覆出現的結果:同一個模型用不同語言問道德兩難,答案常常分屬不同文化象限。所以我賭 DeepSeek 用中文問會明顯左移——但這是賭注不是定論,因為《經濟學人》沒做這個對照。
還有第三個更難排除的因素:這兩款不是基礎模型,是輕量/推理版。R1 是推理模型,Flash 是蒸餾過的小模型。小模型和推理模型本來就傾向給更收斂、更「標準」的答案,變異度低,容易往訓練資料的眾數靠。而那個眾數,因為英文語料佔比高,本來就偏西方。這條和蒸餾糾纏在一起,很難切乾淨。
收束起來:蒸餾是一個合理、有證據的部分解釋,但它無法獨力解釋「比西方還西方」。比較完整的圖像是三股力疊加——蒸餾把 GPT 的對齊指紋帶進來、英文提問把模型推向英語價值空間、輕量/推理版本壓低變異往眾數收斂。三者方向一致,剛好把中文模型一起推到了右上角。
要真正分離出蒸餾的貢獻,唯一的辦法是做對照:同一批題目,中文問一次、英文問一次,看座標移多少。這正是這張圖留下的最大空白,也是它最該被追問的地方。
一點技術上的提醒
最後補一句,免得有人拿這張圖當成鐵證去到處貼。
這張圖的方法欄寫得很小但很關鍵:每個模型的位置是十次回答的平均,題目用英文問,而且設定上把模型輸出的隨機性壓到最低。這三件事每一件都會動搖結論。
十次平均,意味著我們看到的是模型的「中位人格」,看不到它的變異範圍——一個平均落在右上角的模型,可能在不同提問下的擺盪幅度比另一個大得多,而平均值把這個資訊吃掉了。
用英文問,幾乎可以肯定地把所有模型往「英語世界價值」推。前面說 DeepSeek 不靠近中國——但如果改用中文問呢?這張圖沒告訴你。它測的是「模型用英文回答時的價值觀」,不是「模型的價值觀」。這兩者的差距,本身就是這整個議題的核心。
把隨機性壓到最低,測的是模型最「典型」的那一面,不是它能展開的範圍。
所以這張圖該被當成什麼?一張對話的起點,不是一份判決書。它把一個夠真實的現象畫得夠清楚,清楚到值得我們認真讀——但讀的時候要記得,它每一個方法選擇,都在悄悄地塑造你看到的那團紅點該往哪邊靠。
一張地圖永遠不是它所描繪的疆域。這張尤其不是。
圖片來源:The Economist,"Godless hippies",資料取自 World Values Survey Round Seven (R. Inglehart et al., 2022) 及各 AI 模型供應商。本文對圖中各模型座標的描述為作者依圖目視判讀,非原始數據。